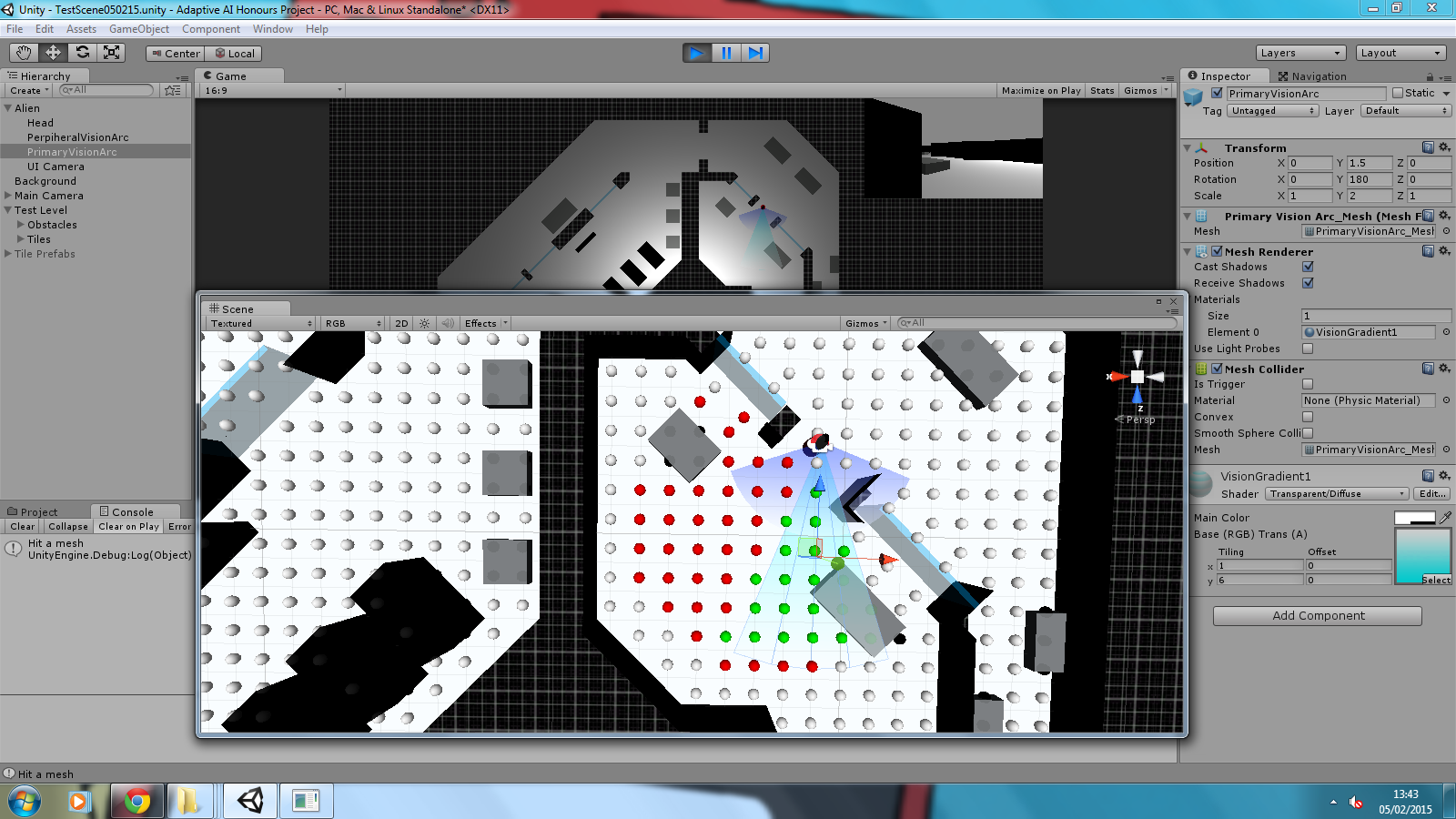
Latest implementation appears to be clustering correctly under given parameters:
– the number of ‘neighbours’ parameter appears to be one higher than expected, the images here are set at 4…
– the minimum distance between neighbours is 1.5f – this is expected as the search nodes are arranged in a 1.0f grid (save a few incorrectly placed tiles
– there does appear to be an issue with noise allocation in this implementation, a final check after the main DBSCAN loop is required to collect some missed nodes

This shot uses the same parameters but over a more complex area, again it appears to identify the search area correctly – including 3 separate clusters (each having their center shown by the blue sphere), and 10 ‘noise’ nodes.

If this currently implementation proves robust enough it will form the basis of the A.I.’s searching function:
– the DBSCAN will return two lists (clusters and noise)
– each will be given a weighted priority based on its size (always one for noise) and the distance of the A.I.’s path to its center
A new list is formed of destinations and weights – allowing the A.I. to search this area.
Larger (clusters) which are closer will have the strongest weighting.
The final thought is not simply for the A.I. to work through this list in order, but for it to choose randomly between them biased by their weighting – the largest nearest cluster would be the logical and most likely outcome, but there would be a small chance of another being chosen.